Intrinsic Self-Supervision for Data Quality Audits
NeurIPS'24Updates
- Now we support SelfClean for Audio! Project website: https://selfclean-audio.github.io

Abstract
Benchmark datasets in computer vision often contain off-topic images, near duplicates, and label errors, leading to inaccurate estimates of model performance. In this paper, we revisit the task of data cleaning and formalize it as either a ranking problem, which significantly reduces human inspection effort, or a scoring problem, which allows for automated decisions based on score distributions. We find that a specific combination of context-aware self-supervised representation learning and distance-based indicators is effective in finding issues without annotation biases. This methodology, which we call SelfClean, surpasses state-of-the-art performance in detecting off-topic images, near duplicates, and label errors within widely-used image datasets, such as ImageNet-1k, Food-101N, and STL-10, both for synthetic issues and real contamination. We apply the detailed method to multiple image benchmarks, identify up to 16% of issues, and confirm an improvement in evaluation reliability upon cleaning.
Citation
@article{groger_selfclean_2024,
title = {{Intrinsic Self-Supervision for Data Quality Audits}},
shorttitle = {{SelfClean}},
author = {Gr\"oger, Fabian and Lionetti, Simone and Gottfrois, Philippe and Gonzalez-Jimenez, Alvaro and Amruthalingam, Ludovic and Consortium, Labelling and Groh, Matthew and Navarini, Alexander A. and Pouly, Marc},
year = 2024,
month = 12,
journal = {Advances in Neural Information Processing Systems (NeurIPS)},
}
Slides
Data Quality Issues in Benchmarks
This section reports the results of auditing multiple vision benchmarks using SelfClean. Below we estimate the number of issues in fully automatic mode. Specifically the table shows the estimated percentage of data quality issues in vision benchmarks obtained using SelfClean's automatic mode with and . Images marked as originating from the same person, patient or lesion were excluded from the near-duplicate count whenever available.
| Dataset | Size | Estimated Off-topic Samples | Estimated Near Duplicates | Estimated Label Errors | Total |
|---|---|---|---|---|---|
| Medical Images | |||||
| DDI | 656 | 1 (0.2%) | 4 (0.6%) | 5 (0.8%) | 10 (1.5%) |
| PAD-UFES-20 | 2,298 | 0 (0.0%) | 0 (0.0%) | 5 (0.4%) | 5 (0.4%) |
| HAM10000 | 11,526 | 0 (0.0%) | 1 (<0.1%) | 17 (0.2%) | 18 (0.2%) |
| VinDr-BodyPartXR | 16,086 | 263 (1.6%) | 20 (0.1%) | 74 (0.5%) | 357 (2.2%) |
| Fitzpatrick17k | 16,574 | 18 (0.1%) | 2,446 (14.8%) | 103 (0.6%) | 2,567 (15.5%) |
| ISIC-2019 | 33,569 | 0 (0.0%) | 1,200 (3.6%) | 97 (0.3%) | 1,297 (3.9%) |
| CheXpert1 | 223,414 | 6 (<0.1%) | 0 (0.0%) | 303 (0.1%) | 309 (0.1%) |
| PatchCamelyon | 327,680 | 98 (<0.1%) | 12,845 (3.9%) | 589 (0.2%) | 13,532 (4.1%) |
| General Images | |||||
| STL-10 | 5,000 | 0 (0.0%) | 7 (0.1%) | 21 (0.4%) | 28 (0.5%) |
| ImageNet-1k Validation | 50,000 | 0 (0.0%) | 36 (0.1%) | 262 (0.5%) | 298 (0.6%) |
| CelebA | 202,599 | 2 (<0.1%) | 810 (0.4%) | 1,033 (0.5%) | 1,845 (0.9%) |
| Food-101N | 310,009 | 310 (0.1%) | 4,433 (1.4%) | 2,728 (0.9%) | 7,471 (2.4%) |
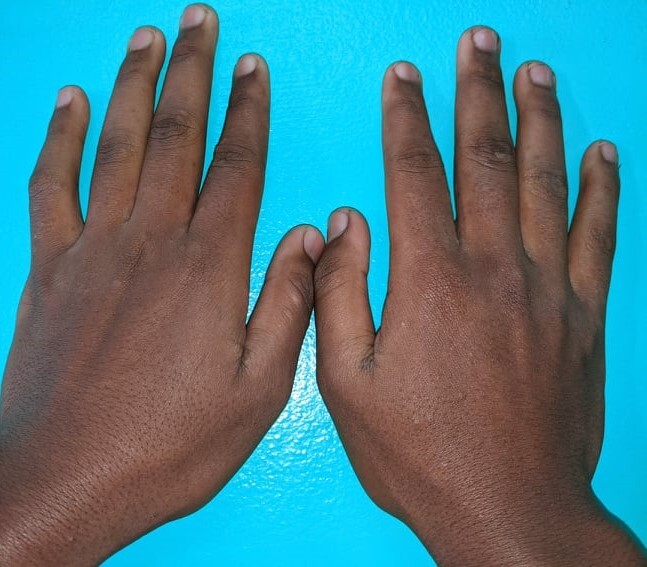
Here we illustrate the rankings by visualizing the top 15 samples of each issue type, namely off-topic samples, near duplicates, and label errors.
ImageNet-1k
Near duplicates: 
Off-topic samples: 
Label errors: 
CheXpert
Near duplicates: 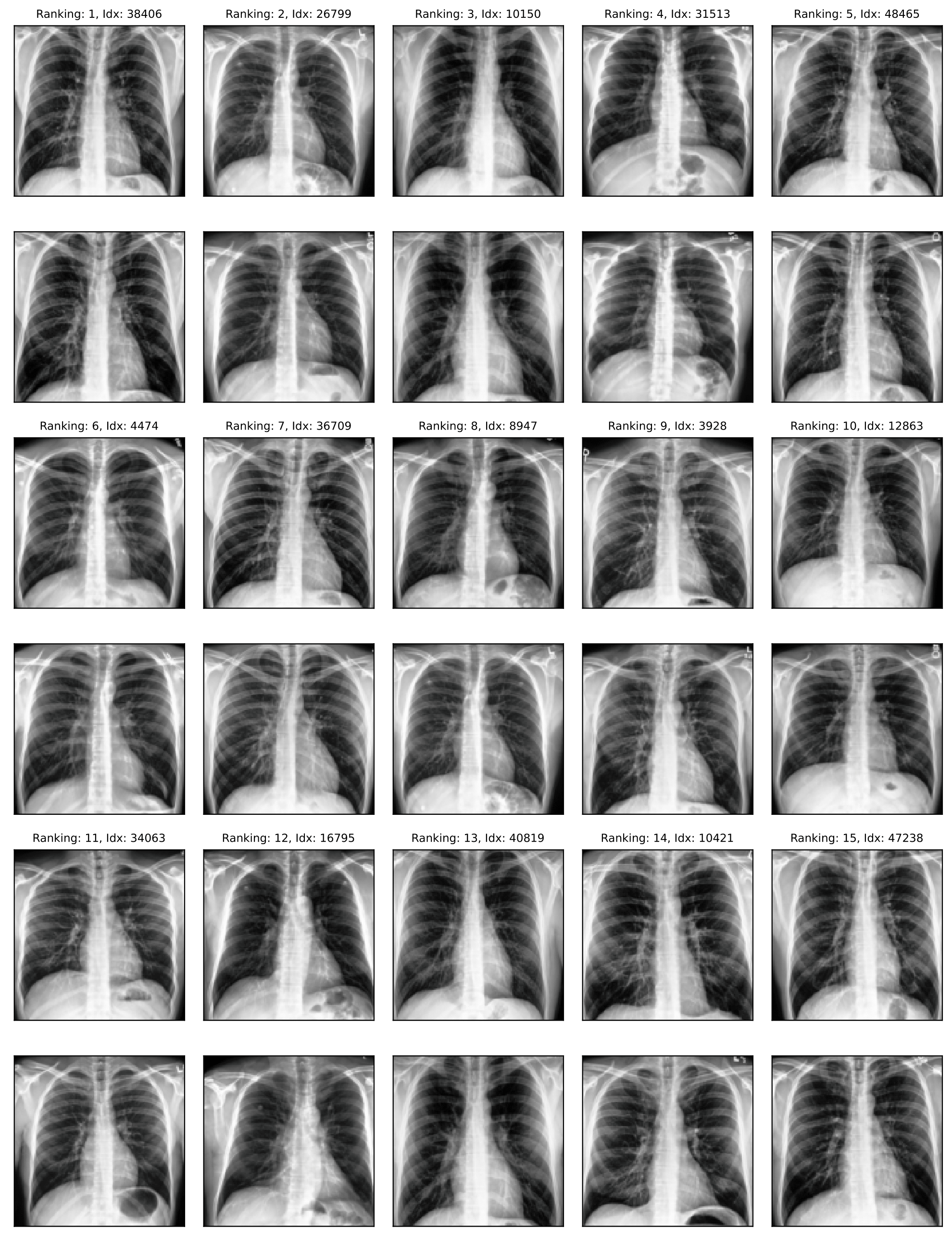
Off-topic samples: 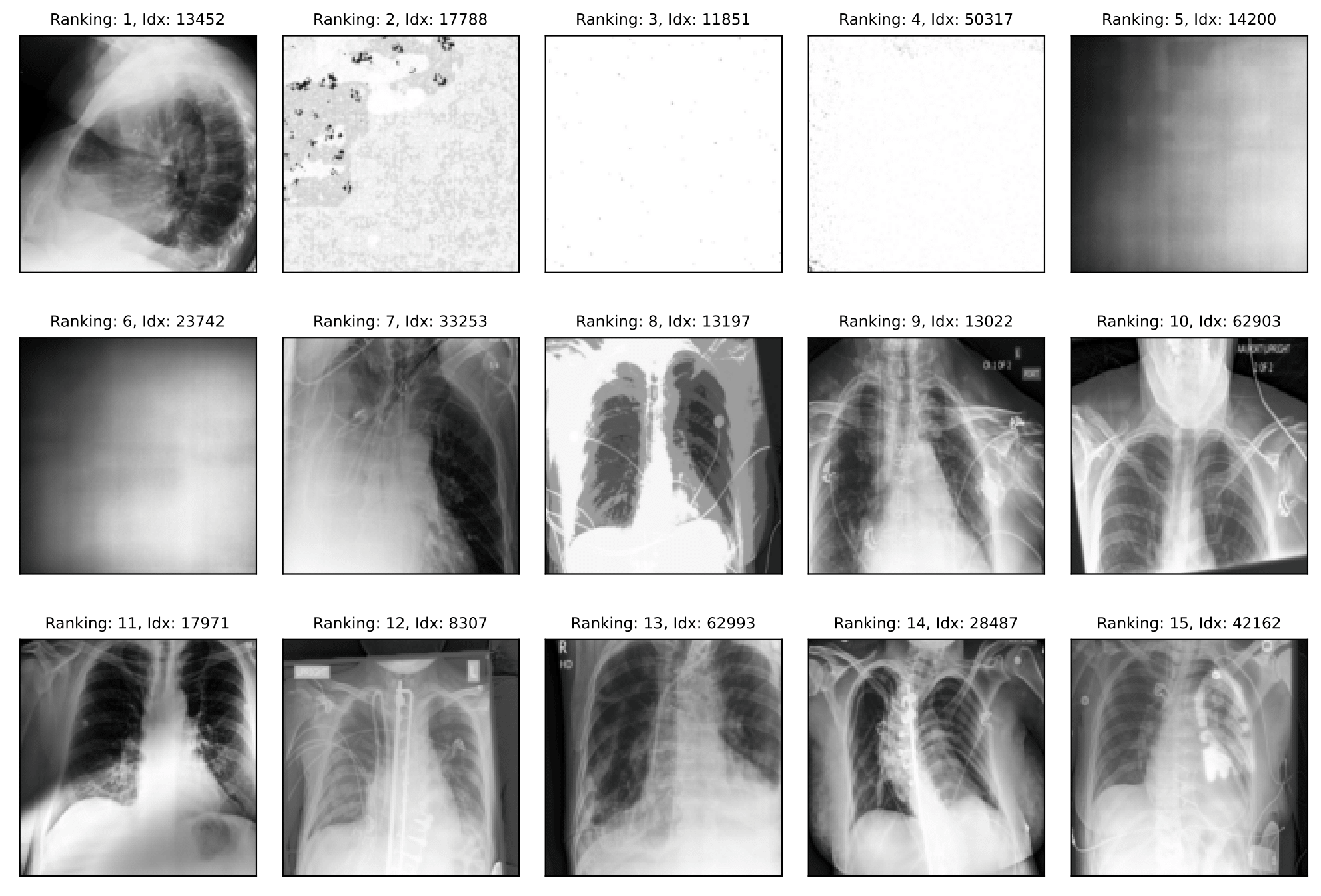
Label errors: 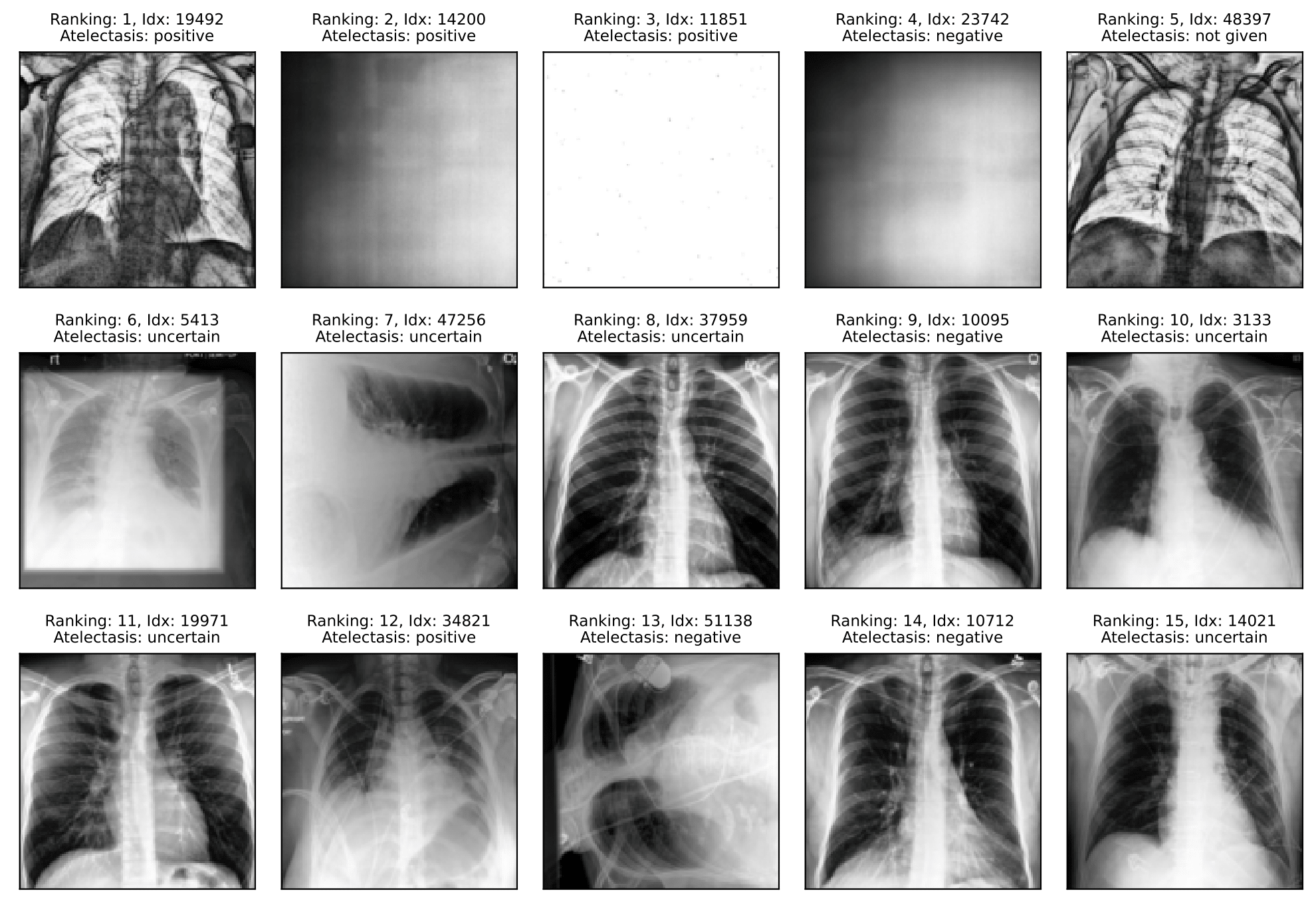
PatchCamelyon
Near duplicates: 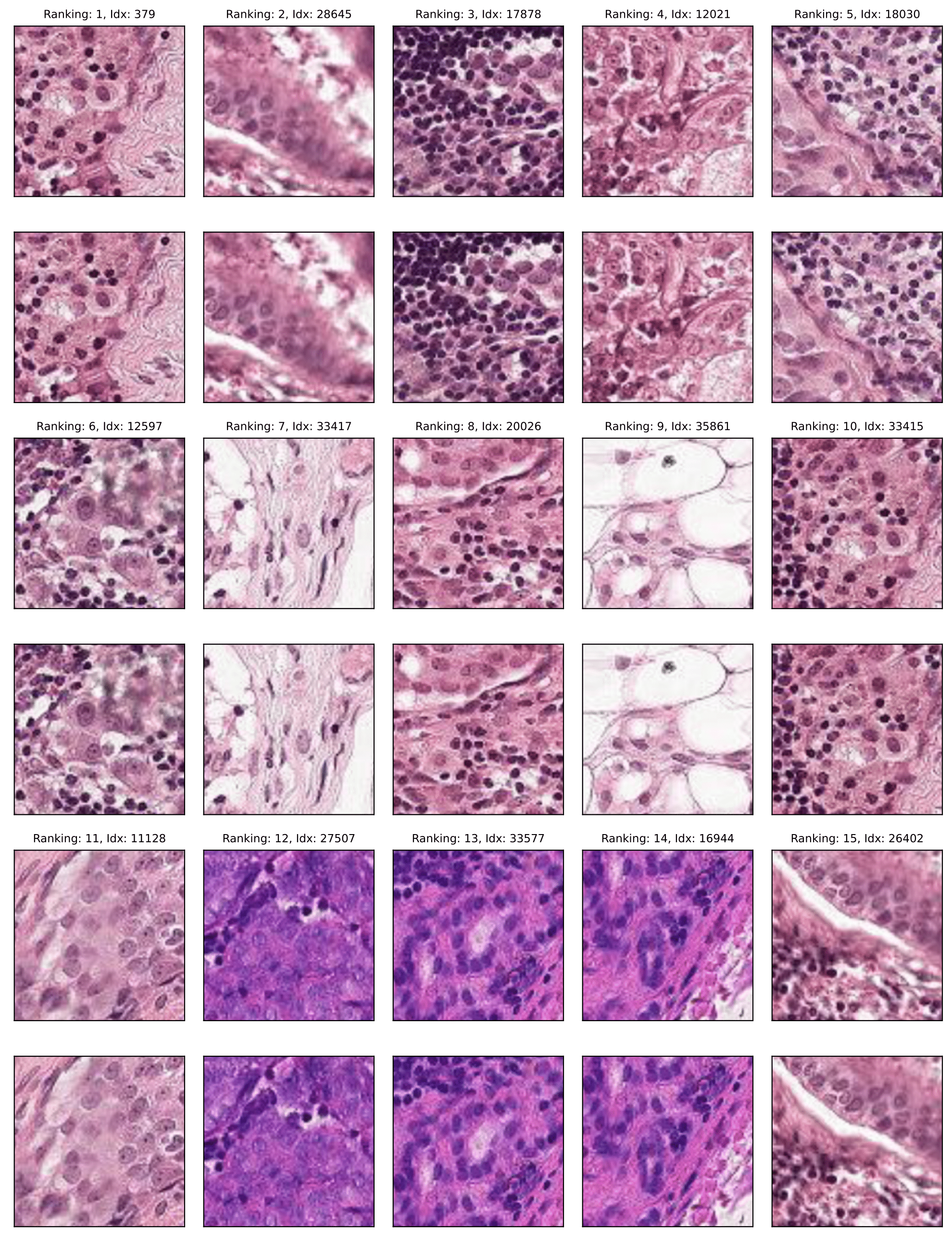
Off-topic samples: 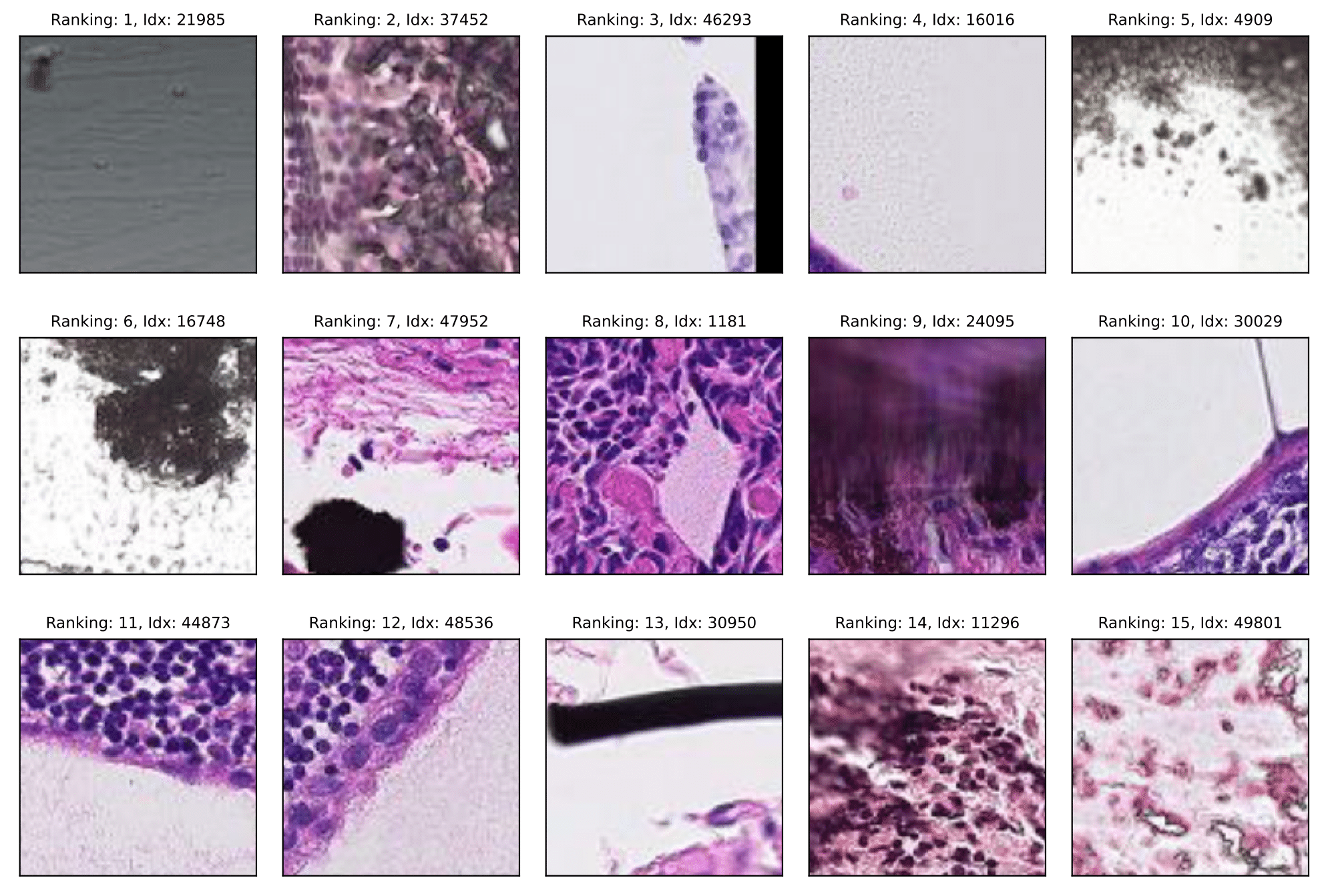
Label errors: 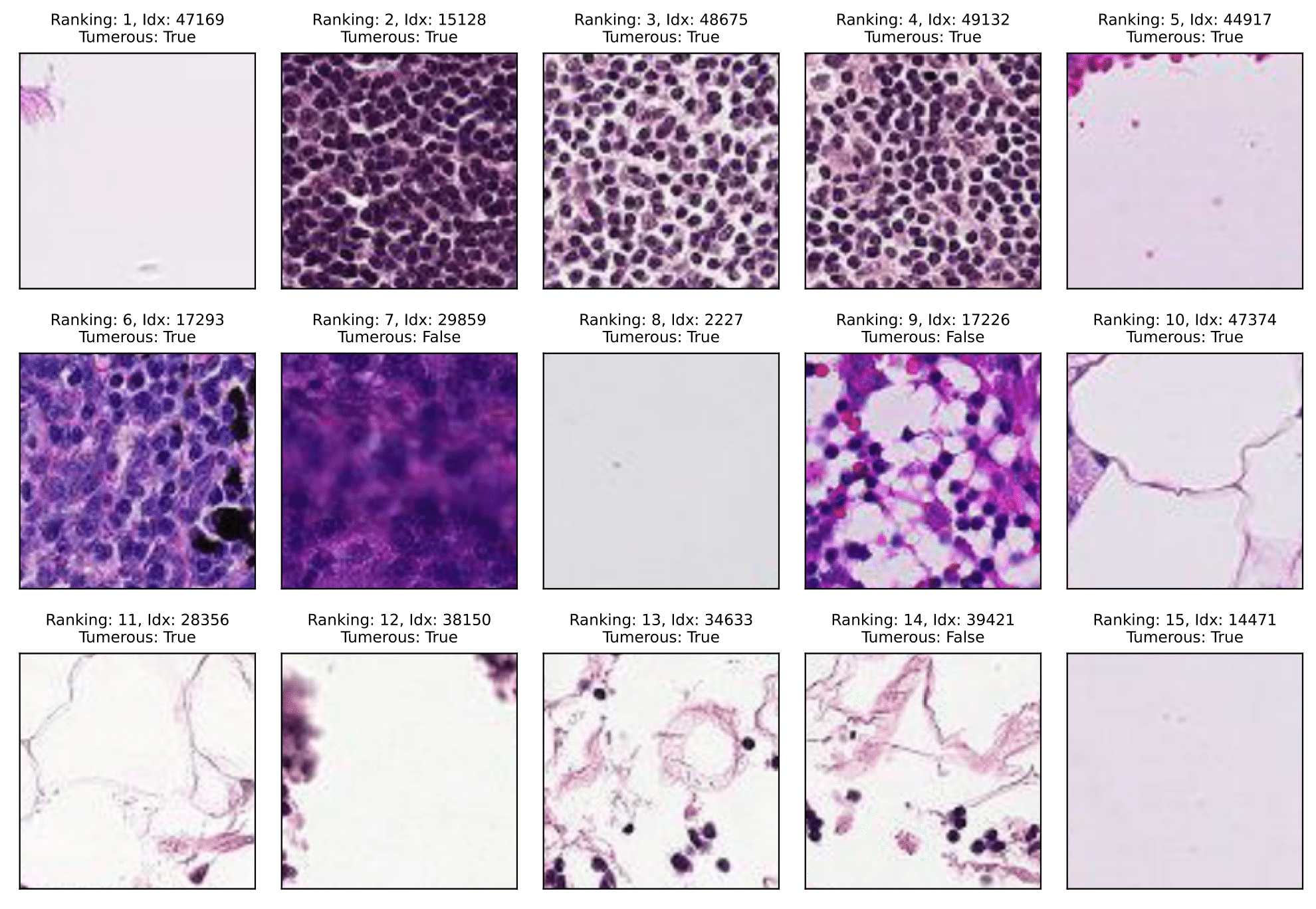
Fitzpatrick17k
Near duplicates: 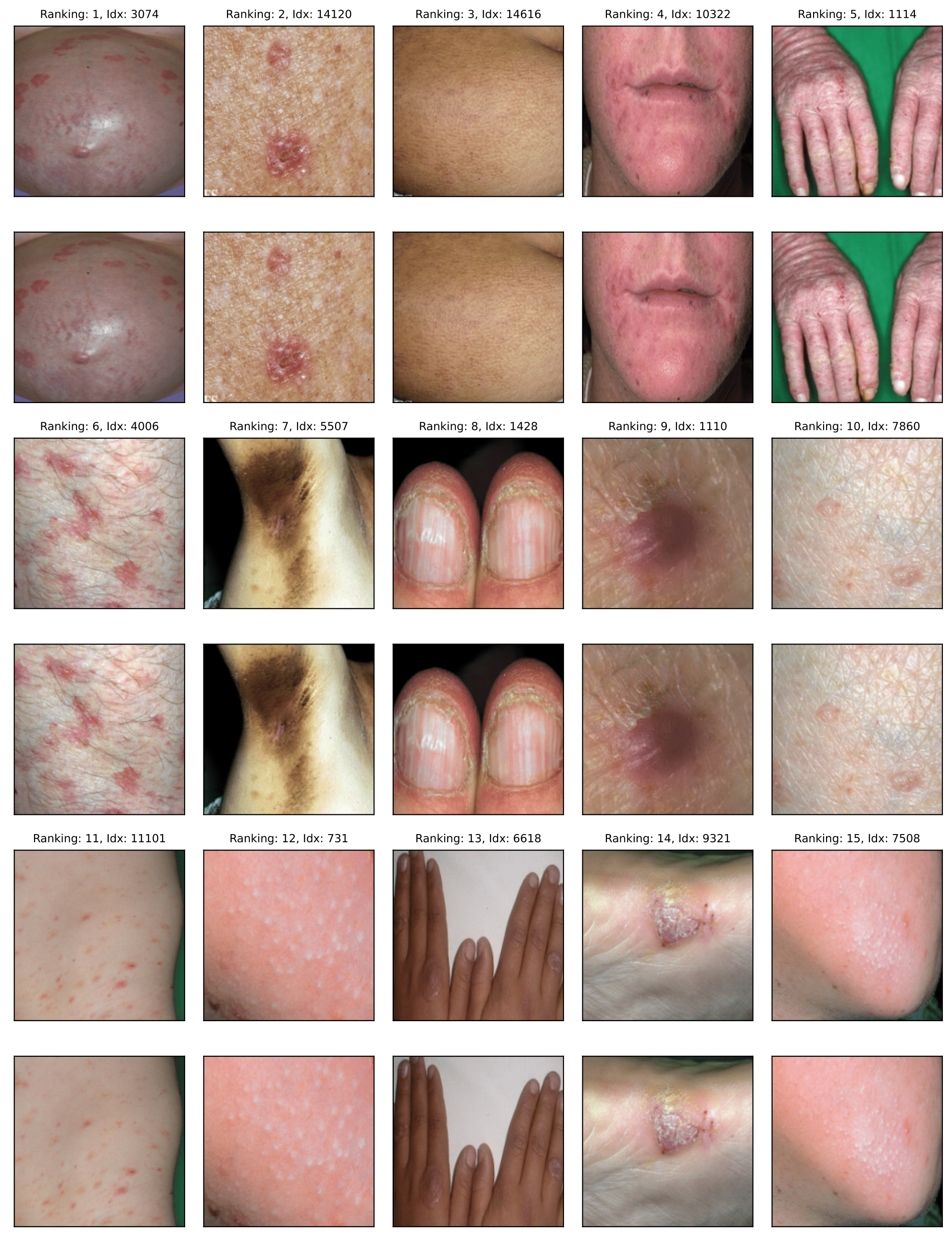
Off-topic samples: 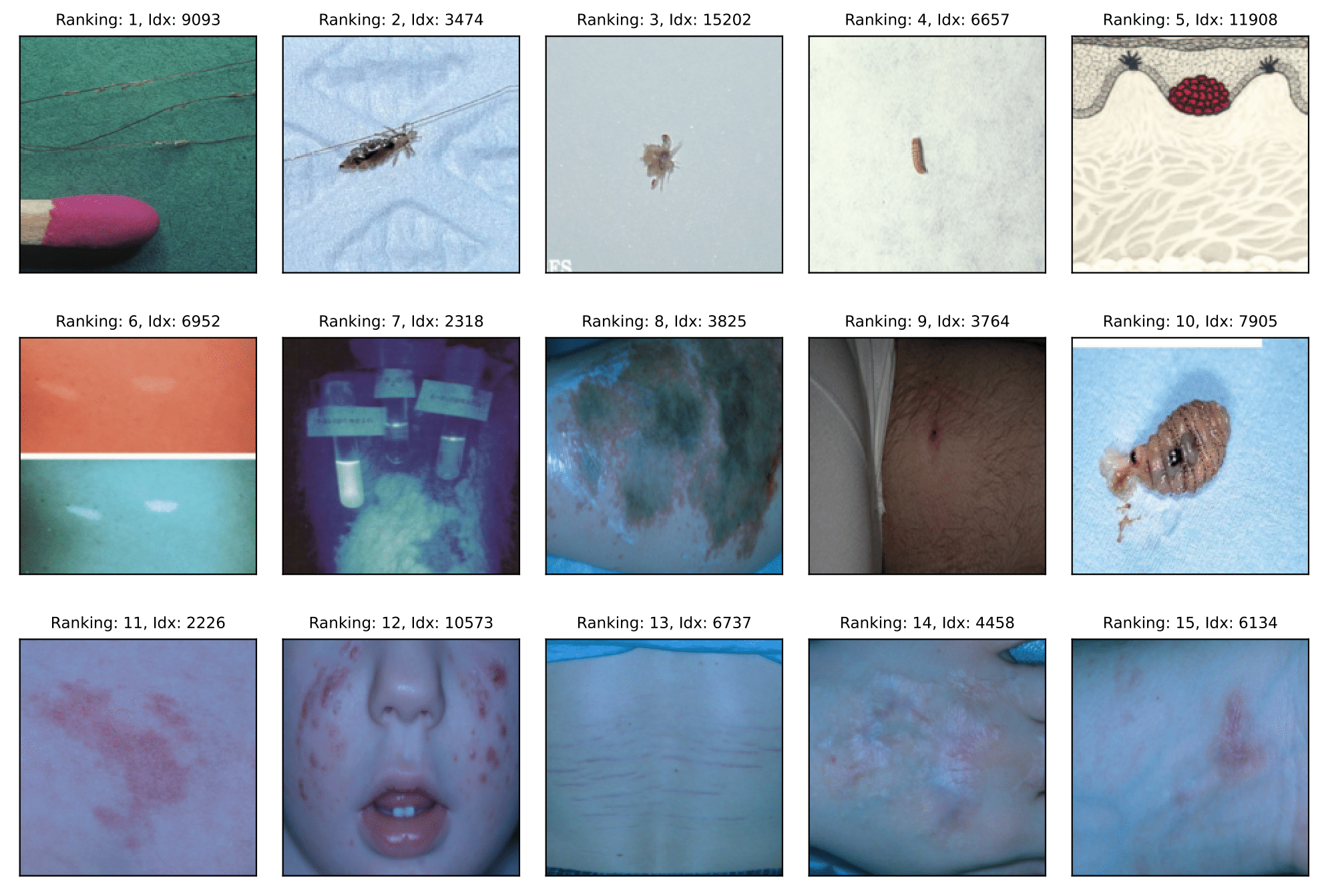
Label errors: 
powered by Academic Project Page Template